Data Model
The Searchlock platform relies on a structured data model designed to store products, price observations, store information, and user tracking data.
The primary goal of the data model is to support:
- efficient storage of price history
- cross-store product comparison
- product tracking by users
- scalable ingestion of scraping results
The database acts as the central integration point between the scraping system, backend API, and frontend application.
Entity Relationship Overview
The system's data structure is defined through a relational model that connects users, products, stores, and price observations.
Below is the Entity Relationship Diagram (ERD) representing the structure of the database.
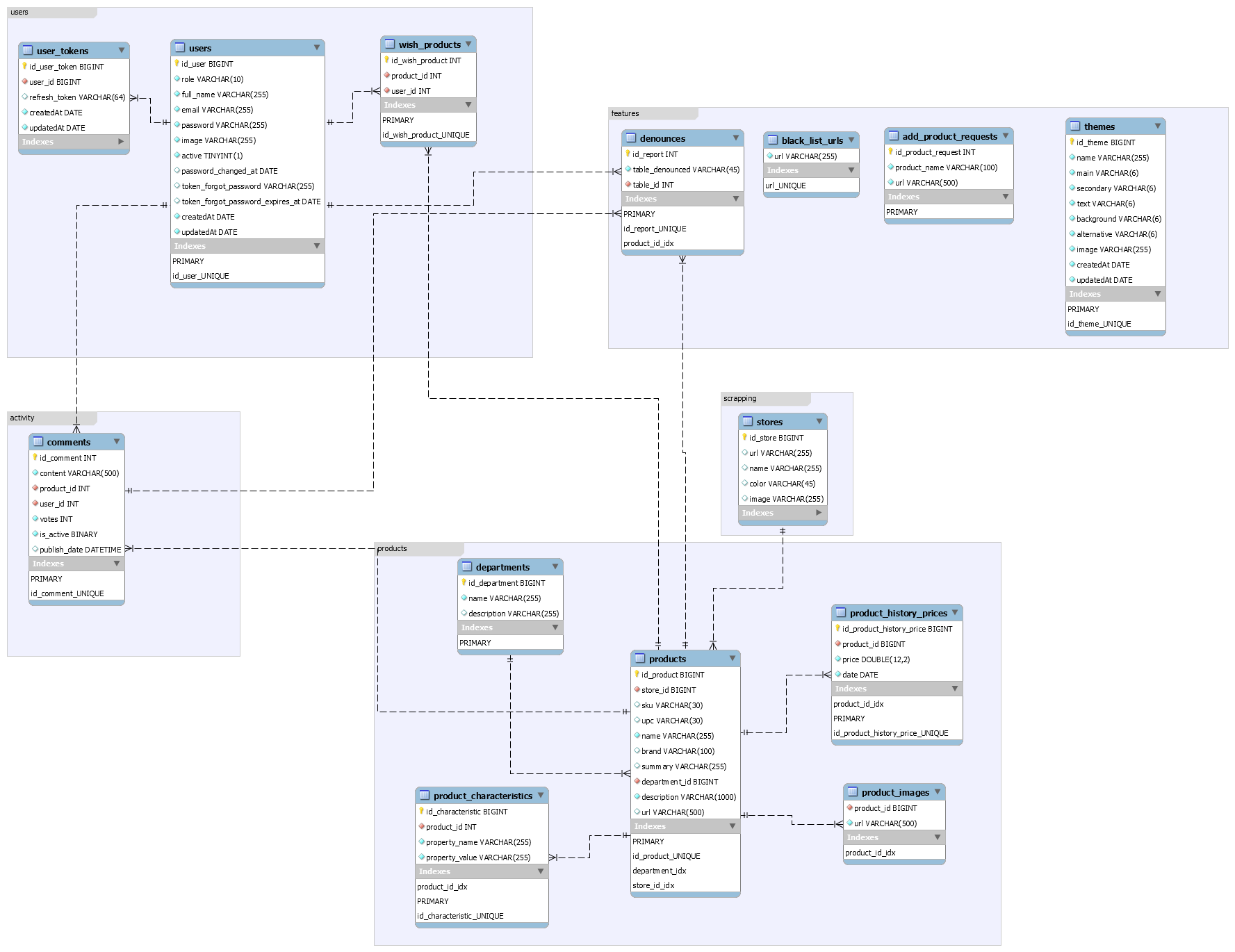
Note: The ER diagram illustrates the relationships between core entities in the platform.
Core Entities
The data model revolves around several primary entities.
Products
The products entity represents individual items that can be tracked across multiple stores.
Typical attributes include:
- product identifier
- product name
- canonical product reference
- metadata associated with the item
Products serve as the central reference point for price tracking across different stores.
Stores
The stores entity represents the e-commerce platforms monitored by the scraping system.
Examples may include online retailers such as electronics stores, marketplaces, or specialized shops.
Typical attributes include:
- store identifier
- store name
- base URL
- store metadata
Each store may contain many products, and each product may appear in multiple stores.
Price Records
The price records entity stores historical price observations collected by the scraping system.
Every time a spider retrieves a product page, a new price record may be generated.
Typical attributes include:
- product identifier
- store identifier
- observed price
- timestamp
- product URL
This table is responsible for maintaining the historical price dataset used for trend analysis and price tracking.
Users
The users entity represents registered users of the platform.
Users interact with the system through the frontend application and may perform actions such as:
- searching for products
- tracking items
- receiving price notifications
Typical attributes include:
- user identifier
- username
- authentication credentials
- account metadata
Product Tracking
The product tracking relationship allows users to follow specific products.
This structure enables the platform to:
- monitor price changes for user-selected products
- trigger notification events
- personalize the user experience
A user may track multiple products, and a product may be tracked by multiple users.
Price History Strategy
One of the most important design choices in the data model is how price history is stored.
Instead of overwriting product prices, the system records every observed price as a new entry.
This approach allows the platform to:
- maintain a complete historical record
- generate price trend graphs
- analyze pricing behavior over time
- detect price drops or spikes
Although this increases the volume of stored data, it enables richer analytics and user features.
Scraping Data Integration
The scraping system interacts directly with the database through the ingestion pipeline.
The typical data flow is:
- A spider extracts product data from a store page.
- The pipeline validates the extracted information.
- The product is matched with an existing record or inserted if new.
- A new price observation is created.
- The historical dataset is updated.
This structure ensures the scraping system can continuously append new price observations without disrupting existing records.
Data Consistency Considerations
Maintaining data consistency is important because scraping systems can produce noisy or inconsistent results.
The platform mitigates these risks through:
- validation within the ingestion pipeline
- normalization of extracted fields
- consistent product identifiers
- store-specific product references
These measures help ensure reliable price tracking and product comparison.
Scalability Considerations
Because the scraping system may generate large volumes of price observations, the data model was designed to handle continuous growth of historical data.
Key considerations include:
- efficient indexing of product identifiers
- timestamp indexing for price history queries
- separation of static product data from dynamic price records
This structure allows the system to efficiently retrieve both current prices and historical trends.
Summary
The data model provides the foundation for storing and organizing all platform data.
By separating products, stores, price observations, and user tracking relationships, the system supports reliable price monitoring, historical analysis, and personalized user features.
The relational design also allows the scraping system, backend API, and frontend application to interact with the same structured dataset while maintaining data integrity.
Next Sections
The next sections describe additional components of the system:
- Backend API — application logic and service layer
- Notification System — user alerts and price change detection
- Engineering Challenges — technical lessons learned during development